Auto reverse-engineering the Hyperliquid risk engine, with some agentic help
Perps allow traders to leverage beyond their collateral, until the market turns abruptly and losses are clawed back. We auto-reverse engineer Hyperliquid’s risk engine to show how it ranks and deleverages winning users under the solvency–fairness–revenue trilemma.
Perpetuals
Definition
A perpetual is a bet on a price, usually leveraged, settled in stablecoins, and with no expiry. It is a row in the exchange’s ledger, backed by margin, where one side’s gains are the other side’s losses on the same book.
What does that even have to do with reverse engineering?
Hyperliquid
Hyperliquid is a decentralized perpetuals exchange. It runs on its own L1, released publicly for anybody to run, but closed source. The order book and the risk engine live on-chain, and thus inside of the L1 node binary, sitting between users and the shared balance sheet they’re all betting against.
The node has a very hard problem. It must keep the books balanced when leverage makes it possible for one side of every trade to lose more than their margin covers.
Implementing a correct algorithm that solves this question is exactly what keeps the exchange solvent. This is also why peering into the actual implementation is very intriguing from a security standpoint.
Beyond that, the hl-node binary also offers an additional technical thrill. It is written in Rust, which is notoriously hard to reverse engineer.
Armed with some curiosity, a good amount of inference, and the right tooling, we’ll take a deep dive into the reconstructed code so that anybody can follow along, while also giving reverse engineers something to learn.
The million dollar question
Let’s say a terrible trader opens a 50x leveraged position on Hyperliquid. How does the exchange avoid losing money from their eventual downfall?
When the market turns against them, the first check they would encounter is the traditional liquidation. Their position is automatically put up on the market on the opposite side of the book. This happens whenever the equity of the position drops below the maintenance margin, which is spelled out exactly in the compute_margin_requirement_by_mode() function.
Start with the simplest case, an isolated position. The relevant function is compute_account_value_for_direction().
compute_account_value_for_direction()int64_t sub_555556bb4d20(int64_t arg1, int64_t arg2, int64_t arg3, int64_t arg4, int64_t arg5, int64_t arg6)struct OptionUnitQty* compute_account_value_for_direction(struct OptionUnitQty* result, struct UserState* user_state, uint8_t is_isolated, uint64_t asset_idx, uint32_t margin_mode, void* oracle_data)The important part is the argument list. The function receives a UserState, an isolated or cross selector, an asset index, a margin mode, and oracle data.
The body splits on is_isolated. Cross margin takes the account-wide path, while isolated margin continues into the single-position calculation.
compute_account_value_for_direction()struct OptionUnitQty* compute_account_value_for_direction(struct OptionUnitQty* result, struct UserState* user_state, uint8_t is_isolated, uint64_t asset_idx, uint32_t margin_mode, void* oracle_data){4 collapsed lines
int128_t var_138; struct OptionUnitQty lhs; int64_t rax, rcx, rdx; bool cond;
if (!(is_isolated & 1)) { // Cross margin computes account-wide value and shortfall. compute_user_margin_and_shortfall(&var_138, user_state, oracle_data, nullptr); return result; }
// Isolated margin uses this asset's margin and own PnL.}The important detail is that isolated equity is local to the position. It is the isolated margin plus the position’s own PnL. From there the threshold reduces to this expression.
What if nobody wants to buy the position?
The market order from the previous section is just a regular order, and it still needs somebody on the other side of the book to fill it. If the book is thin or the move was violent enough that every passive bid got swept, only part of it (or none) gets filled and equity will possibly keep on going down.
When that happens, the exchange is basically left with a hot potato to get rid of. What should it even do with the debt?
The risk engine
And now we circle back to the risk engine. In order to keep all of these terrible traders from driving the system into ruin, we need some automatic way to prevent and clear bad debt.
The Hyperliquid docs explain that positions below 2/3 maintenance margin are backstop-liquidated into the HLP liquidator vault. When even that can’t keep the book solvent, auto-deleveraging closes the position against opposing traders. What does that even mean?
To get a better idea of what’s going on here, we turn to the binary itself and trace the actual logic. A simple testnet sync gives us a lot of context. Within the node’s ABCI state, we can see a pretty complex structure named Clearinghouse, a struct containing all liquidation-related info, nested within a bigger Exchange data structure. This is an example of what it might hold when serialized as MessagePack at runtime (download the sample dump, 234 MB).
This data will come in handy both for us and the agent.
Now, when does the risk engine actually check positions? We can answer that question by playing around with xrefs starting from the known field strings in Clearinghouse. Some renaming later, the call path looks like this:
We have one huge function handling all clearinghouse operations, which we call clearinghouse_adl_orchestrator(). It is invoked at the end of each block by a top-level method (called indirectly elsewhere, most likely a trait method) that we call exchange_end_block(). So, at the end of each block we run some checks.
Take the only_isolated branch, which fast-tracks certain assets straight to deleveraging:
int64_t var_28 = *(arg1 + 8);if (*(arg2 + (var_28 << 5) + 0x18) != 0) { if (LOGGER_ONCE_CELL != 3) once_cell_get_or_init(&LOGGER_ONCE_CELL, 0, &var_a0, &data_55555878bb08); int64_t rax_11 = rust_alloc(0x34); __builtin_strncpy(rax_11, "immediately auto-deleveraging only_isolated position", 0x34); // ...append entry...}int64_t entry_asset_idx = *(ph1_entry_ptr + 8);if (clearinghouse->asset_count <= entry_asset_idx) panic_index_out_of_bounds(entry_asset_idx, clearinghouse->asset_count);
if (*(clearinghouse->asset_array_ptr + (entry_asset_idx << 5) + 0x18)) // asset.strict_isolated != 0{ if (LOGGER_ONCE_CELL != 3) once_cell_get_or_init(&LOGGER_ONCE_CELL, 0, &scratch_opt, &data_55555878bb08); int64_t rax_11 = rust_alloc(0x34); __builtin_strncpy(rax_11, "immediately auto-deleveraging only_isolated position", 0x34); // ...append to the deferred queue...}if asset_strict_isolated(ch, *asset_idx) { fill_ctx.log_lines.push(String::from("immediately auto-deleveraging only_isolated position")); deferred_cross_queue.push((*counterparty_addr, *asset_idx));}This branch gives us the first ADL shortcut. Strict isolated assets bypass the normal aggregate-shortfall gate and go straight into the ADL queue.
From there, the ADL path has a clean four-phase shape:
clearinghouse_adl_orchestrator()98 collapsed lines
use std::collections::{BTreeMap, HashMap};
pub struct OptionUnitQty { pub tag: u64, pub unit: u64, pub value: i64,}
pub struct UserState { pub acct_value: OptionUnitQty, pub margin_used: OptionUnitQty, pub positions: BTreeMap<u64, [u64; 17]>, pub funding_state: OptionUnitQty,}
pub struct AssetConfig { pub coin: String, pub strict_isolated: bool, pub spot_only: bool, pub max_leverage: u16, pub asset_flags: u32,}
pub struct OraclePrice { pub mark: u64, pub oracle: u64, pub mid: u64, pub funding_rate: u64, pub spot: u64, pub last_trade: u64, pub min_size: u64, pub tick_size: u64, pub szi: u64, pub usd_value: u64, pub interest: u64, pub volume: u64,}
pub struct OracleData { pub prices: Vec<OraclePrice>, pub recent_oi: BTreeMap<u64, OptionUnitQty>,}
pub struct AdlFillTracker { pub log_lines: Vec<String>, pub pending_fills: Vec<u64>, pub fill_list_idx: u64, pub asset_to_fills: String, pub block_time_us: u64,}
pub struct Clearinghouse { pub total_net_deposit: OptionUnitQty, pub total_non_bridge_deposit: OptionUnitQty, pub adl_shortfall_remaining: OptionUnitQty, pub bridge2_withdraw_fee: OptionUnitQty, pub default_user_state: UserState, pub lookup_asset_ref: u64, pub assets: &'static [AssetConfig], pub oracle_prices: Vec<OraclePrice>, pub oracle_funding: OptionUnitQty, pub oracle_misc: OptionUnitQty, pub margin_tables: BTreeMap<u64, u64>, pub user_states: BTreeMap<[u8; 20], UserState>, pub vault_states: HashMap<[u8; 20], u64>, pub spot_balances: HashMap<[u8; 20], u64>, pub spot_meta: HashMap<u64, u64>, pub builder_fees: BTreeMap<u64, u64>, pub asset_recent_oi: BTreeMap<u64, u64>, pub perform_auto_deleveraging: bool,}
fn ouq_value(quote: &OptionUnitQty) -> i64 { quote.value }
fn account_value_for_direction(_user: &UserState, _asset_idx: u64, _oracle: &OracleData) -> OptionUnitQty { OptionUnitQty { tag: 0, unit: 0, value: 0 }}
fn margin_and_shortfall(_user: &UserState, _oracle: &OracleData) -> OptionUnitQty { OptionUnitQty { tag: 0, unit: 0, value: 0 }}
fn build_counterparty_fills(_ch: &Clearinghouse, _ctx: &mut AdlFillTracker, _oracle: &mut OracleData, _addr: &[u8; 20], _asset_idx: u64) -> Vec<u8> { Vec::new()}
fn process_counterparty_fill(_ch: &Clearinghouse, _ctx: &mut AdlFillTracker, _oracle: &mut OracleData, _asset_idx: u64, _direction: u8, _byte: u8) -> i64 { 0}
fn lookup_user_state<'a>(ch: &'a Clearinghouse, counterparty_addr: &[u8; 20]) -> &'a UserState { ch.user_states.get(counterparty_addr).unwrap_or(&ch.default_user_state)}
fn asset_strict_isolated(ch: &Clearinghouse, asset_idx: u64) -> bool { ch.assets.get(asset_idx as usize).map(|a| a.strict_isolated).unwrap_or(false)}
pub fn clearinghouse_adl_orchestrator(ch: &Clearinghouse, fill_ctx: &mut AdlFillTracker, oracle: &mut OracleData, candidates: &BTreeMap<[u8; 20], u64>) -> BTreeMap<(u64, u8), Vec<u8>> { let mut result: BTreeMap<(u64, u8), Vec<u8>> = BTreeMap::new(); let mut total_shortfall_value: i64 = 0; let mut deferred_cross_queue: Vec<([u8; 20], u64)> = Vec::new();
let mut pointer = candidates.iter(); while let Some((counterparty_addr, asset_idx)) = pointer.next() { let user_state = lookup_user_state(ch, counterparty_addr); let user_shortfall = account_value_for_direction(user_state, *asset_idx, oracle); let value = ouq_value(&user_shortfall); if value > 0 { panic!("Bug! ADL candidate account value was not negative"); } if asset_strict_isolated(ch, *asset_idx) { fill_ctx.log_lines.push(String::from("immediately auto-deleveraging only_isolated position")); deferred_cross_queue.push((*counterparty_addr, *asset_idx)); } else { total_shortfall_value = total_shortfall_value.wrapping_sub(value); } }
let remaining_shortfall = ch.adl_shortfall_remaining.value; let adl_was_triggered = total_shortfall_value >= remaining_shortfall; if adl_was_triggered { deferred_cross_queue.clear(); let mut pointer_1 = candidates.iter(); while let Some((counterparty_addr, asset_idx)) = pointer_1.next() { deferred_cross_queue.push((*counterparty_addr, *asset_idx)); } }
let mut counterparty_array: Vec<[u8; 20]> = Vec::new(); let mut pointer_2 = deferred_cross_queue.iter(); while let Some(&(counterparty_addr, asset_idx)) = pointer_2.next() { let user_state = lookup_user_state(ch, &counterparty_addr); let cpty_abs_position = margin_and_shortfall(user_state, oracle); let _ = cpty_abs_position; counterparty_array.push(counterparty_addr); let counterparty_info = build_counterparty_fills(ch, fill_ctx, oracle, &counterparty_addr, asset_idx); result.insert((asset_idx, 0u8), counterparty_info); } let counterparty_count = counterparty_array.len(); let _ = counterparty_count;
let mut pointer_3 = result.iter_mut(); while let Some((&(asset_idx, expected_kind), counterparty_info)) = pointer_3.next() { let length = counterparty_info.len(); let mut i: usize = 0; while i < length { let cpty_addr_bytes = counterparty_info[i]; let fill_delta = process_counterparty_fill(ch, fill_ctx, oracle, asset_idx, expected_kind, cpty_addr_bytes); let _ = fill_delta; i = i.wrapping_add(1); } }
if !ch.perform_auto_deleveraging { result.clear(); } result}ADL is meant as an emergency measure. Unlike liquidations, it is not always operational. In this view, the flag appears as a final guard. Unless clearinghouse.perform_auto_deleveraging is set, the result is cleared before returning.
clearinghouse_adl_orchestrator() if !ch.perform_auto_deleveraging { result.clear(); } result}Note (Execution gate)
The lower-level decompilation is more precise here. In the binary view, perform_auto_deleveraging gates the actual forced-close call inside Phase 4.
if (!clearinghouse_1->perform_auto_deleveraging) goto label_555556ac74ce;
r9_6 = adl_process_counterparty_position(clearinghouse_1, asset_idx_1, &entry_addr_raw, &fill_delta, &insolvent_user_addr, r9_5);So read the final result.clear() as a compact model of a no-execute mode, not as the literal place where the binary enforces the flag.
Most importantly, for it to act it must actually be needed. What does that mean according to the Clearinghouse?
Threshold condition
The natural connection between liquidations and ADL is shortfall, which measures how much a position, or the entire system (!), is underwater.
If we could liquidate every position in time against willing buyers of the debt, there would be no systemic shortfall. ADL is triggered whenever that’s not the case.
Who is underwater?
In order to determine that shortfall (or sum of bad debt)1, we process a useful tree of losing positions, built at the end of each block and passed to the clearinghouse_adl_orchestrator(), starting from all user positions, which are stored in clearinghouse.user_states, as we can also see from the serialization.
The adl_init_user_position_iterators() essentially turns that into an Iter, then, inside of build_adl_candidate_set() each entry is accounted either as a cross or isolated position, depending on the value of the AdlIterEntry field.
struct AdlIterContextstruct AdlIterContext { uint8_t* direction_ptr; struct OracleState* oracle_ptr;};Note that in storage, Isolated positions have their own independent Entry in the position iterators, and Cross positions have a single common Entry, which will be spread across several perps. We will see many more branches to handle the two kinds of positions.
build_adl_candidate_set()while (true){ int64_t shortfall_tag = entry_cursor->margin_type; if (shortfall_tag != 2) { int64_t asset_idx = entry_cursor->asset_idx; }}Ultimately, we get an iterator of underwater users. Phase 1’s classify loop keeps only the entries whose account value is non-positive, which are the ones that could not be liquidated by the end of the block according to the earlier threshold. A positive value panics, since a solvent account should never reach ADL.
After iterating over users, if the total losses are less than a predefined constant (hardcoded to $5M in the testnet state), we spare cross-margin positions and log Not performing auto-deleveraging because shortfall={} is acceptable.
Note that this insurance fund is not applied to every asset. While this isn’t documented anywhere, markets referred to as only_isolated (or strict_isolated in MessagePack dumps) are added to a separate queue, deferred_queue, which triggers ADL regardless of the system’s total_shortfall. This is the strict_isolated branch in Phase 1 that we stepped through earlier.
Very interestingly, some of the assets that have this flag, at least on testnet, include HYPE (and other relevant tokens like ZRO, as well as JELLYJELLY from the March 2025 incident). Historical metadata for Hyperliquid is very hard to come by, so take this with a pinch of salt when thinking about mainnet.2
How do we get rid of debt?
Now we know whenever we have shortfall. What is to be done in that case? This is where different risk engines make different design choices. Hyperliquid chooses to apply a queue-based ADL system, meaning they forcefully close some winning positions in order to clear the debt of the losing traders.
Thus, if the debt is insurmountable, the deferred_queue is overwritten by all the users marked by build_adl_candidate_set(). Otherwise we keep it, and only holders of underwater strict_isolated positions from the earlier loop are considered for ADL. That fork is Phase 2’s gate:
clearinghouse_adl_orchestrator()let remaining_shortfall = ch.adl_shortfall_remaining.value;let adl_was_triggered = total_shortfall_value >= remaining_shortfall;if adl_was_triggered { deferred_cross_queue.clear(); let mut pointer_1 = candidates.iter(); while let Some((counterparty_addr, asset_idx)) = pointer_1.next() { deferred_cross_queue.push((*counterparty_addr, *asset_idx)); }}For each underwater position, Phase 3 does a B-tree lookup on clearinghouse.user_states[position.user] through the recovered lookup_user_state() helper and pushes the user onto a Vec. You would be amazed at how long the compilation of such a simple statement is. This is the push alone, growth check included:
clearinghouse_adl_orchestrator()if (cpty_vec_count == cpty_vec_cap) OPTION_UNIT_QTY_NONE_2 = vec_grow_0x28(&cpty_vec_cap);
int64_t rcx_11 = cpty_vec_count * 5;*(cpty_vec_ptr + (rcx_11 << 3) + 0x10) = scratch_opt.set.height;OPTION_UNIT_QTY_NONE_2 = scratch_opt.tag;*(&OPTION_UNIT_QTY_NONE_2 + 8) = scratch_opt.set.root_ptr;*(cpty_vec_ptr + (rcx_11 << 3)) = OPTION_UNIT_QTY_NONE_2;*(cpty_vec_ptr + (rcx_11 << 3) + 0x18) = deferred_entry_tag;*(cpty_vec_ptr + (rcx_11 << 3) + 0x20) = entry_addr_raw_1;cpty_vec_count += 1;The logic for cross margin positions is more complicated, because we’re essentially asking the question of how to split a bankrupt user’s total shortfall across their individual positions, so that we can absorb the right proportion of each position. The natural split is to weight each position by its share of total cross notional:
In the four-phase sketch above, that proportional split is represented by the build_counterparty_fills() stub:
clearinghouse_adl_orchestrator()fn build_counterparty_fills(_ch: &Clearinghouse, _ctx: &mut AdlFillTracker, _oracle: &mut OracleData, _addr: &[u8; 20], _asset_idx: u64) -> Vec<u8> { Vec::new()}The real version spans all (asset_idx, direction) held in the cross margin position, weighting each by the formula above.
For isolated positions the computation is trivial, and we directly write the single position, with its shortfall, to the adl_output B-tree, which is the output of this transformation for both isolated and cross margin positions, containing both position_id and position_shortfall.
Afterwards we can finally loop over the B-tree containing (position_id, cut), which essentially tells us exactly how much of each position needs to be closed, to be later deleveraged from a winning position.
The final phase of clearinghouse_adl_orchestrator() iterates it, and for each key it builds a counterparty array, initially including all users holding positions, sorting them based on a per-asset ADL ranking score.3
How are positions chosen (sorted) to be deleveraged?
Who do we deleverage?
This question is essential to the solvency and fairness of a perp platform. It is clear why solvency is a priority here.
But what do we mean by fairness? Colloquially, we can say that the relative wealth of accounts should not be affected by deleveraging.
More formally, fairness can be given multiple related definitions. See this paper for one treatment. We want to prove that the algorithm used in HL is not axiomatically fair in its implementation, as defined in prop. 6.1 of the paper.
So, is Hyperliquid fair? Is it always solvent?
ADL score computation
The score function at compute_adl_ranking_score() is core to answering this question. It’s defined, most likely as an Ord implementation on some 20-byte address representation. A Vec of those holds the possible counterparties to fill against, and the trait is used by the sort routines that order them by ranking score for each underwater position.
Those sort routines are generated by the compiler. Since Rust binaries include a lot of metadata by default in .comment, we may even manually take advantage of this to recover the exact source of library functions.
Let’s see how this ties back into the clearinghouse_adl_orchestrator():
The sort itself is generated by the compiler, so there is no single hand-written call site to point at. The orchestrator hands its counterparties to those routines, which call back into compute_adl_ranking_score() for every comparison.
Ratio 1: effective leverage
Definition (Effective leverage)
In the recovered score function, the first ratio is the position’s absolute notional over its account value, which is the risk multiplier the user took on.
compute_adl_ranking_score()let abs_notional = (signed_notional_product as f64).abs();let account_value = result_2.account_value_unit.qty as f64;let ratio1_margin_ratio = (abs_notional / account_value).max(1e-8);Note (Operand check)
The lower-level decompiler comment around label_555556abb73f labels this ratio as account_value / abs_notional, but the raw instruction operands settle it the other way. The numerator uses the unsigned u64 → f64 SIMD conversion pattern, which matches abs_notional. The denominator uses signed cvtsi2sd, which matches account_value. The final divsd computes numerator over denominator.
Ratio 2: profit ratio
Definition (Profit ratio)
The second ratio divides the position’s PnL, clamped to non-negative, by its entry notional, telling us how well the user’s bet went.[^4]
compute_adl_ranking_score()let result_4 = (signed_notional_product + entry_notional_1).max(0) as f64;let result = ratio1_margin_ratio * (result_4 / (entry_notional_4 as f64)).max(1e-8);There is clamping to avoid rounding issues. Both ratios are clamped to a minimum of 1e-8, in order not to cancel each other out. The final ADL ranking score is effective_leverage * profit_ratio, consistent with both the recovered Rust and the raw operand check.
Intuition
We look for risky and profitable positions!
Partial and total ADL
Finally, note that deleveraging can also be partial, but even then it goes by the order defined by this score.
Here, we fork based on whether ADL is total or not, closing the position in the former case. In the binary view, that decision compares the counterparty’s position size against the shortfall left to fill:
clearinghouse_adl_orchestrator()if (cpty_pos_size <= fill_remaining_check_2){ // Full fill pops the consumed counterparty and takes the entire position. cpty_ranking_count -= 1; // ... fill_delta.value = cpty_pos_abs_szi;}So essentially, the whole latter part of clearinghouse_adl_orchestrator() boils down to Phase 4, which runs the fills per asset and direction:
clearinghouse_adl_orchestrator()let mut pointer_3 = result.iter_mut();while let Some((&(asset_idx, expected_kind), counterparty_info)) = pointer_3.next() { let length = counterparty_info.len(); let mut i: usize = 0; while i < length { let cpty_addr_bytes = counterparty_info[i]; let fill_delta = process_counterparty_fill(ch, fill_ctx, oracle, asset_idx, expected_kind, cpty_addr_bytes); let _ = fill_delta; i = i.wrapping_add(1); }}The execution-gate caveat above applies to this call.4 The binary only performs the forced-close operation when perform_auto_deleveraging is set.
Note that fill.pos_szi is the full position size of the insolvent user, not just the position shortfall. This is key to understanding the financial implications of ADL.
Branches
There is still much to be explored here. We could try to take a leap forward and conjecture some financial conclusions from what we’ve learned so far, or we could take a step back and do some introspection on the tools that made this all possible.
Given the polar opposite direction of those two ends, the author has decided to let the reader choose their own adventure.
Financial conclusions
Fairness, revenue, solvency trilemma
Aligning with the trilemma proposed in §2.1, prop. 2.5 of the paper mentioned before, let’s try to quantify a concrete estimate for each axis of the trilemma:
- Solvency measures whether the platform can pay every trader out.
- Fairness uses the axiomatic fairness definition per prop. 3.4.
- Revenue measures the fraction of total winner PNL that survives after deleveraging.
Let’s borrow these definitions from the paper.
Notation
Here, is the mark price from different sources, is the insurance fund, roughly the 5M on testnet HL, is PNL for longs and negated for shorts, and is the positive part of PNL.
And let’s make the trilemma definitions concrete.
- Solvency is . It measures how much of the total bad debt was actually covered. means fully solvent (), while means nothing was recovered.
- Fairness is , where for each winner with . It measures how uniformly the haircut burden is distributed across profitable traders. means everyone loses the same fraction of their PNL. means a few get wiped while most are untouched.
- Revenue is . Here is the haircut capacity, or total positive PNL, after going through a policy .
We can now simulate these values for both Hyperliquid and Percolator, a new pro-rata based perp engine developed by Anatoly Yakovenko (github.com/aeyakovenko/percolator).
We fix an a priori price path to simulate two cases. The first is a crash followed by a recovery, and the second is a crash followed by an equally severe second crash. This is the most common reason for deleveraging, but the opposite move could also trigger the same machinery.
One prediction that we can make is that Percolator is perfectly fair according to this scoring because the are the same for everyone. The Gini coefficient must therefore be 0.
We are ignoring the a posteriori price impact that deleveraging causes (read about the Oct 10 crash analysis in that paper). Cross-margin leverage is also interesting because it introduces more correlation between cross-traded assets, while with Percolator we have one risk engine per asset (slab).
Hyperliquid also has an interesting caveat we showed earlier, as it operates with a conditional insurance fund. We will simulate a single asset for now, but this influences the equation when we have multiple assets being traded in either isolated or cross-margin mode.
Simulations
Let’s consider the following price scenarios:
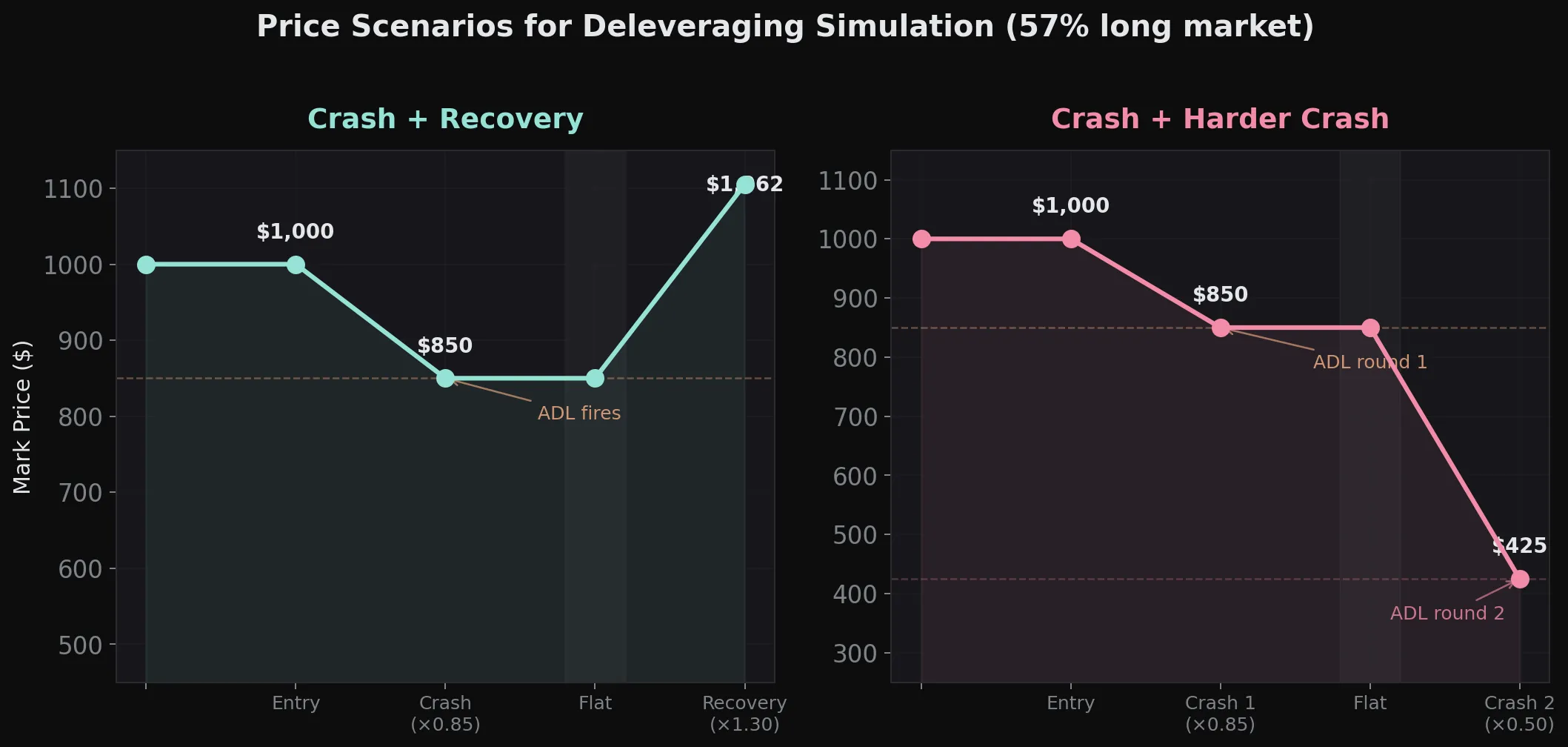
Running this simulation of both systems with a Python reimplementation yields these results:
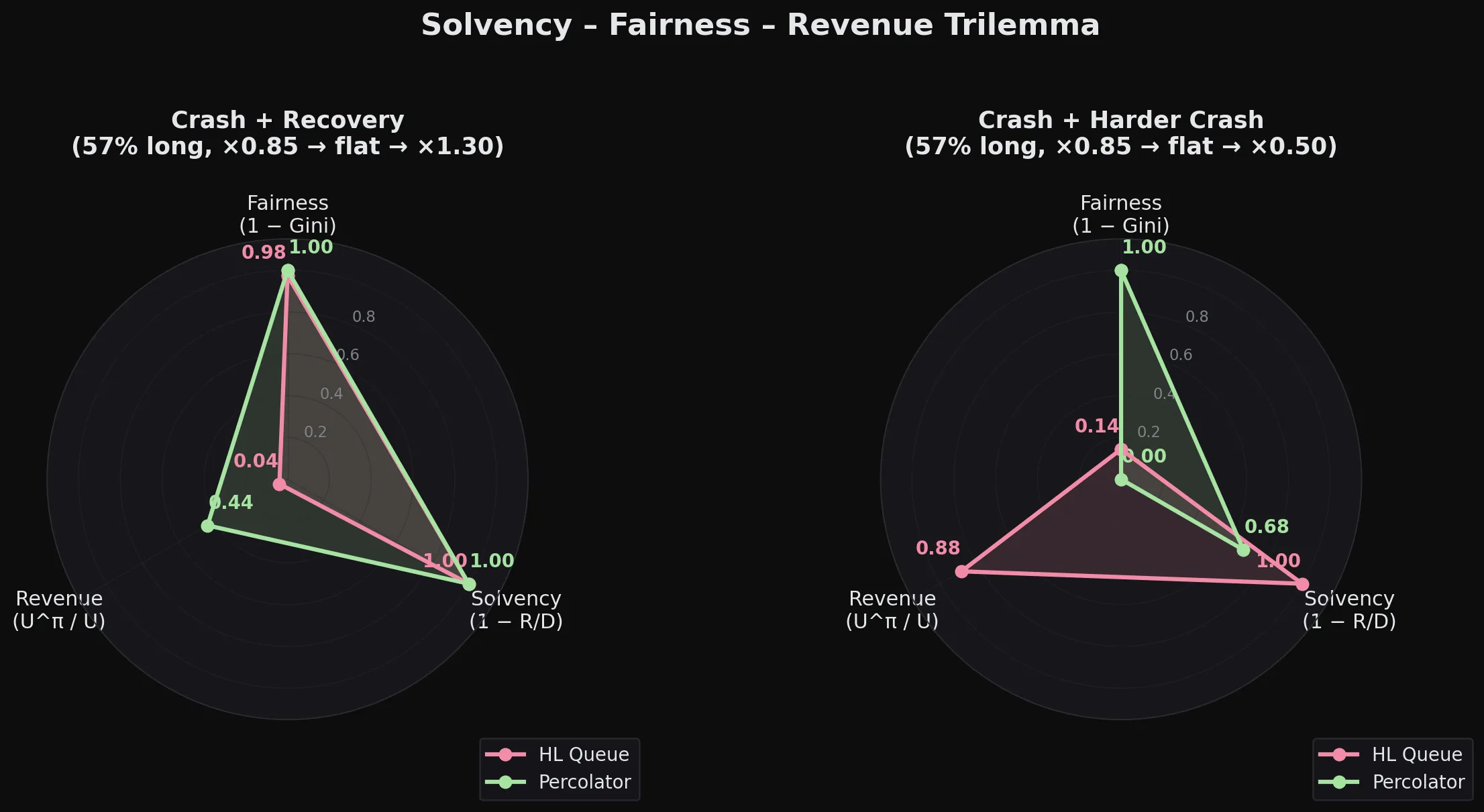
Percolator is more “optimistic”
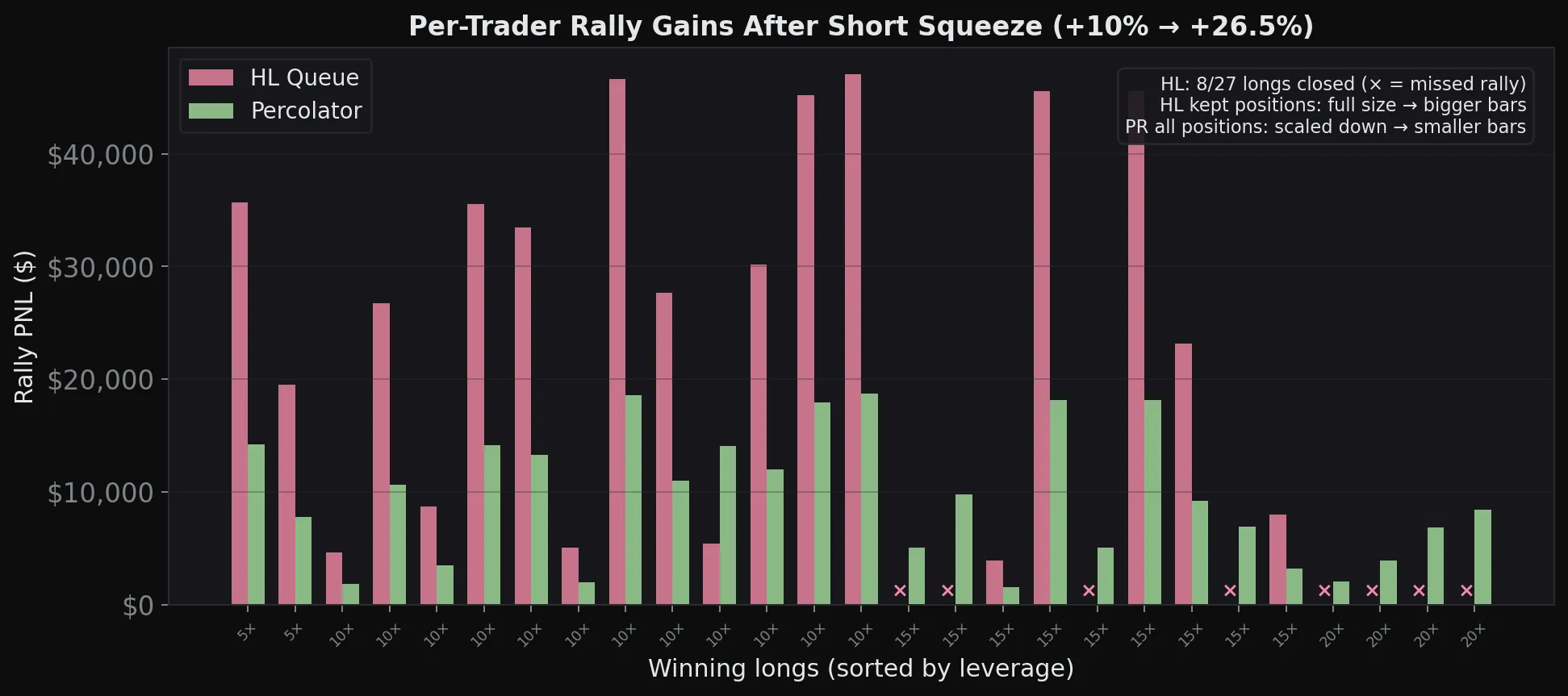
The key difference is what happens to positions. ADL permanently closes them. If the market keeps moving in your favor, tough luck, you’re already out and have to re-enter at the new price. Percolator only reduces what you can withdraw, but the position stays open. If conditions improve, Residual goes up, h climbs back toward 1, and you get your PNL back without doing anything.
We can see this in a short squeeze scenario (60% short market, price +10%). HL’s queue closes 8 of the 27 winning longs — those traders get zero if the rally continues. Under Percolator, all 27 keep their full positions (only the withdrawable profit is reduced by the uniform haircut) and all participate in the continued move. Note that HL’s surviving positions are at full size, so they individually capture more per position, though the tradeoff is that fewer traders get to participate.
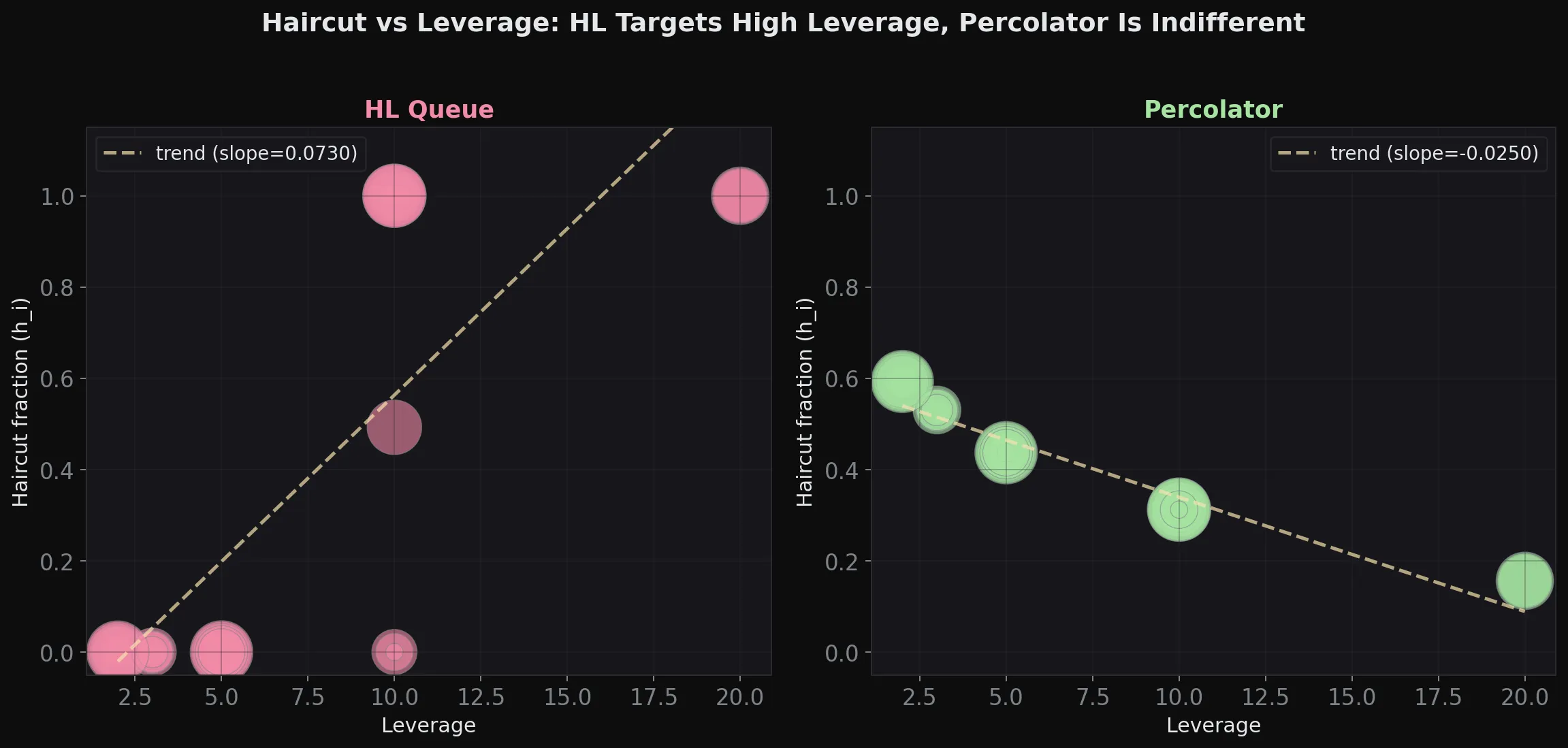
Percolator is indifferent to leverage
We can prove that this is quite the opposite for Hyperliquid, as we’ve traced the implementation of the ADL algorithm, which disproportionately targets higher leverage.
Fairness
A point made in the same paper is that Hyperliquid is “antifair”. The node implementation chooses positions in descending score order, closes them, and leaves everything else untouched.
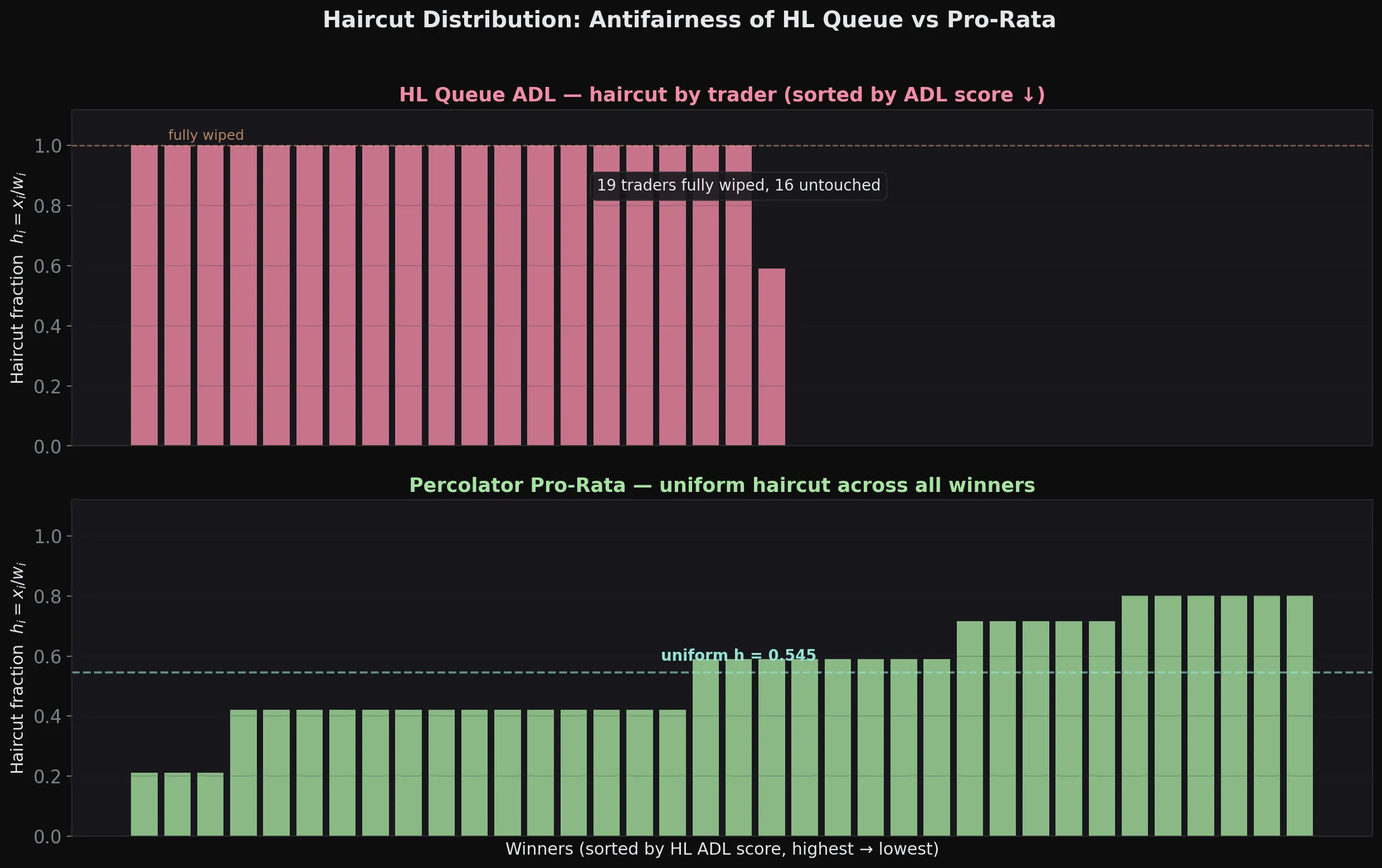
The paper already states in prop. 8.1 that queue-based algos like HL reach solvency faster. We can see that by looking at how ADL is triggered. In clearinghouse_adl_orchestrator() we start by fully closing the worst position against the best-performing trader.
Strengths and limitations of agents for reverse engineering
In general, the lion’s share of the work is done by the underlying model, save for very straightforward tasks. Pushing the model too hard toward a fixed set of possible conclusions usually makes it worse at search problems.
Hooks
Tools are excellent at checking the agent’s work via hooks. The agent proposes a solution to an uncertain problem, such as type recovery, and the hook checks whether that type has compatible offsets and nested pointers compared to what is really used at the assembly level. We applied a similar, simpler check to data flow in the reconstructed Rust snippets.
At the same time, there’s a very thin line between readable output with no validation, and output that is unreadable but technically passes according to the hook. In general, hooks trade time and readability for concrete properties that can be checked at each stage, for example whether the Rust sample compiles and uses variables that map 1 to the disassembly.
Scale
The second lesson to be learned is that agents really shine at scale. Newer models can hold more context than the best reverse engineers out there, so using them for bulk looped tasks like renaming many functions is optimal.
That being said, agents are also far more overconfident than the best reverse engineers. In setups where the agent has tools that “write” to the decompiler view, wrong guesses compounded across recovery stages. The tool layer helped by forcing failed guesses back into analysis, which gave the agent more data before it tried the harder questions again.
What’s next?
This is by no means a strict scientific verdict, but rather some field notes. The public source code for the agents and their tools can be found over at this GitHub repo.
The analyzed binary is available as hl-node (53 MB).
Closing words
As much as it would be exciting to say that everything can be cracked open and studied in the age of LLMs, there are still some gaps to bridge.
Flagship models got us 60% of the way there, but a lot of manual work is still required. We still need to document patterns in the Rust compiler, distill that knowledge onto agents and tools, and understand the “whys” behind a program, beyond the technical question of the “what”.
Still, there is no doubt that LLMs have greatly accelerated progress in the field, and the dream of throwing a well-armed swarm of agents at an ugly blob of machine code to extract meaningful and, most importantly, correct representations and source code is nearing.
We hope to be part of that future, where even complex and obfuscated systems will be verifiable at a glance.
Footnotes
-
compute_user_margin_and_shortfall()is a ubiquitous function for accounting. In its main branch, we loop over a B-tree (note the repeating offsets0x748in the abstract expressions ofbtree_cursor) of per-user positions, branching out based on cross/isolated positions (in order to know what to consider for notional). ↩ -
Some of the historical data from Hyperliquid can be retrieved via the
s3://hl-mainnet-node-data/explorer_blocksS3 bucket. ↩ -
Some loop iterations within the ADL code look very inefficient. For example, we seem to sort and come up with sorted counterparties for each position to be absorbed. ↩
-
ADL crashes the node upon failure. Specifically, if we don’t manage to complete all of the fills against anybody, an assertion in the loop fails. ↩